先放涛哥的博客文章链接
https://kawaii-jump.github.io/2019/10/20/WeeklyContest159/
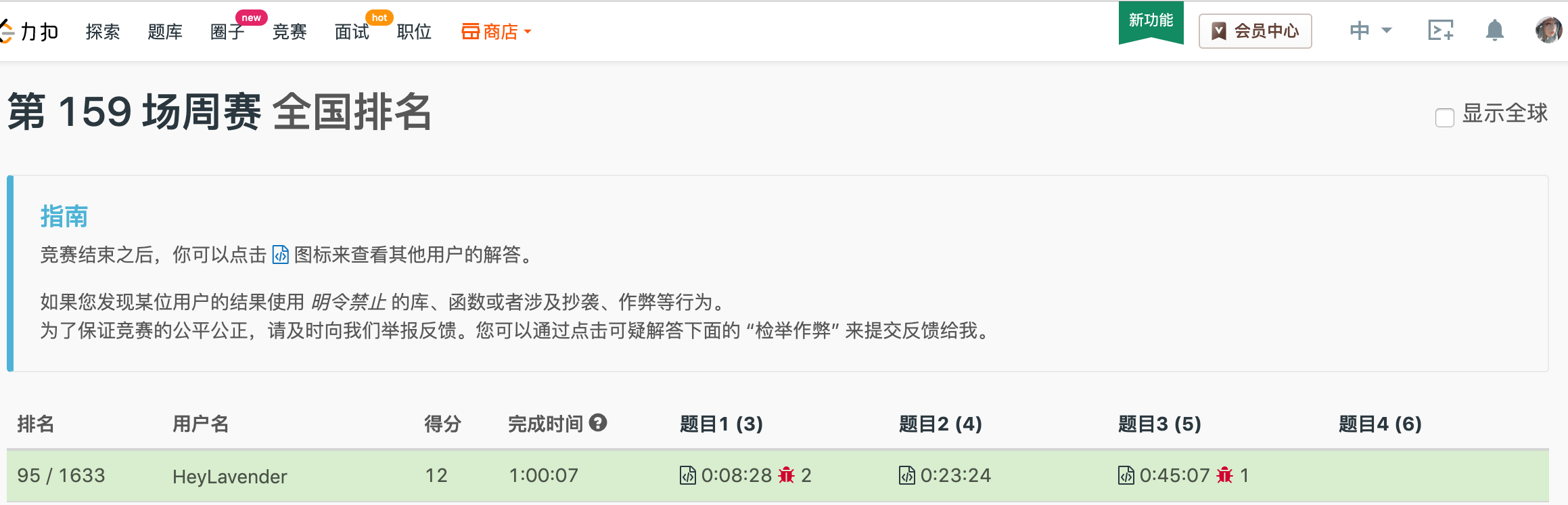
终于不再是掉分场了!
我胡汉三终于逆袭了一波!

周赛传送门
https://leetcode-cn.com/contest/weekly-contest-159
5230. 缀点成线
题目
在一个 XY 坐标系中有一些点,我们用数组 coordinates 来分别记录它们的坐标,其中 coordinates[i] = [x, y] 表示横坐标为 x、纵坐标为 y 的点。
请你来判断,这些点是否在该坐标系中属于同一条直线上,是则返回 true,否则请返回 false。
示例 1:

1 | 输入:coordinates = [[1,2],[2,3],[3,4],[4,5],[5,6],[6,7]] |
示例 2:

1 | 输入:coordinates = [[1,1],[2,2],[3,4],[4,5],[5,6],[7,7]] |
提示:
2 <= coordinates.length <= 1000coordinates[i].length == 2-10^4 <= coordinates[i][0], coordinates[i][1] <= 10^4coordinates中不含重复的点
题解
第一题水了水了,我用斜率公式直接判断的,所以就会产生分母为零的尴尬问题,最后由于情况紧急直接特判过的
1 | class Solution { |
我这个略显麻烦了,还是直接先从两个点直接算出$k$然后$y=kx+b$就好了(顺便吐槽一下用前两个点算$k$官方居然没有分母为0的数据卡人,让我涛哥溜过去了)
5231. 删除子文件夹
题目
你是一位系统管理员,手里有一份文件夹列表 folder,你的任务是要删除该列表中的所有 子文件夹,并以 任意顺序 返回剩下的文件夹。
我们这样定义「子文件夹」:
- 如果文件夹
folder[i]位于另一个文件夹folder[j]下,那么folder[i]就是folder[j]的子文件夹。
文件夹的「路径」是由一个或多个按以下格式串联形成的字符串:
/后跟一个或者多个小写英文字母。
例如,/leetcode 和 /leetcode/problems 都是有效的路径,而空字符串和 / 不是。
示例 1:
1 | 输入:folder = ["/a","/a/b","/c/d","/c/d/e","/c/f"] |
示例 2:
1 | 输入:folder = ["/a","/a/b/c","/a/b/d"] |
示例 3:
1 | 输入:folder = ["/a/b/c","/a/b/d","/a/b/ca"] |
提示:
1 <= folder.length <= 4 * 10^42 <= folder[i].length <= 100folder[i]只包含小写字母和/folder[i]总是以字符/起始- 每个文件夹名都是唯一的
题解
一个比较简单的set的应用,但是难点在于C++没有split函数需要手动切分字符串。你懂的,手动切分就代表了需要考虑边界问题,需要细(还好我经验老道哈哈哈,一次AC)
另一个注意点就是需要首先对字符串进行排序,是按照长度从小到大排序,一个C++的lambda函数即可
最后就是索然无味的set判断,已经有前缀了这个字符串就可以筛掉了,如果一直到最后都没有被筛掉说明它可以留下做别人的前缀,所以加进set里去
1 | class Solution { |
5232. 替换子串得到平衡字符串
题目
有一个只含有 'Q', 'W', 'E', 'R' 四种字符,且长度为 n 的字符串。
假如在该字符串中,这四个字符都恰好出现 n/4 次,那么它就是一个「平衡字符串」。
给你一个这样的字符串 s,请通过「替换子串」的方式,使原字符串 s 变成一个「平衡字符串」。
你可以用和「待替换子串」长度相同的 任何 其他字符串来完成替换。
请返回待替换子串的最小可能长度。
如果原字符串自身就是一个平衡字符串,则返回 0。
示例 1:
1 | 输入:s = "QWER" |
示例 2:
1 | 输入:s = "QQWE" |
示例 3:
1 | 输入:s = "QQQW" |
示例 4:
1 | 输入:s = "QQQQ" |
提示:
1 <= s.length <= 10^5s.length是4的倍数s中只含有'Q','W','E','R'四种字符
题解
第三题一开始以为是个SB题(著名数数算法),最后青蛙发现水有点热了
题目里说了替换子串,所以并不能直接计数解决,需要找到符合条件的子串,怎么找呢?不难想到使用双指针算法(滑动窗口)解决问题
双指针没什么好说的,注意边界条件
注意特判等于0的情况
1 | class Solution { |
5233. 规划兼职工作
题目
你打算利用空闲时间来做兼职工作赚些零花钱。
这里有 n 份兼职工作,每份工作预计从 startTime[i] 开始到 endTime[i] 结束,报酬为 profit[i]。
给你一份兼职工作表,包含开始时间 startTime,结束时间 endTime 和预计报酬 profit 三个数组,请你计算并返回可以获得的最大报酬。
注意,时间上出现重叠的 2 份工作不能同时进行。
如果你选择的工作在时间 X 结束,那么你可以立刻进行在时间 X 开始的下一份工作。
示例 1:

1 | 输入:startTime = [1,2,3,3], endTime = [3,4,5,6], profit = [50,10,40,70] |
示例 2:

1 | 输入:startTime = [1,2,3,4,6], endTime = [3,5,10,6,9], profit = [20,20,100,70,60] |
示例 3:

1 | 输入:startTime = [1,1,1], endTime = [2,3,4], profit = [5,6,4] |
提示:
1 <= startTime.length == endTime.length == profit.length <= 5 * 10^41 <= startTime[i] < endTime[i] <= 10^91 <= profit[i] <= 10^4
题解
烧脑预警!!!
首先放一下一个看起来差不多但是其实有点区别的hdu题
http://acm.hdu.edu.cn/showproblem.php?pid=2037
这道题是以前刷杭电的时候做的题目,但是区间是没有价值的,只要求算最大区间数量,很明显这题是个贪心
然后我做这个周赛第四题时也用了,结果果不其然炸了
最后看了一下别人的思路晚上终于A了这题
首先这题可以说是在贪心上做了一个升级,所以必定是一个dp问题,至于转移方程嘛,需要分类谈论。在讨论转移方程之前,我们首先需要离散化区间的端点(因为端点太大了一个数组放不下,数组存不了dp个毛线)
好的现在我们假装已经离散化了所有的区间端点,然后我们可以将所有原端点的值全部改成离散化以后的值(因为离散化并不改变区间相交或不相交的属性)
可以推出离散化之后的1~n(n是离散化之后值的个数)中一定不存在区间内的点,一定是左右端点(这个可以证明,很简单)。所以我们的dp方程就可以按照左端点和右端点分类讨论。
按照闫氏dp思考法,我们的状态表示dp[i]为从开始到i的最大价值,那么dp的计算就要分类讨论:
- $dp[i]=dp[i-1]$,当i为左端点
- dp[i]是i的所有对应左端点的前面的所有dp值的最大值加当前区间的价值,当i为右端点
显而易见第二类的状态转移不好写,首先我们需要记住所有右端点对应的左端点(一个右端点可以对应一堆左端点,因为有重合),所以我采用了数组模拟的邻接表存储信息
还有就是所有左端点对应的位置前面的所有位置的dp的最大值,这里直接使用树状数组维护信息,找到左端点直接get最大值即可,每次$O(logn)$的复杂度,找到最大值后加上右端点对应的区间价值,再更新$dp[i]$
最后通过这两个转移找到$dp[i]$的最大值,不要忘记更新树状数组
1 | const int maxn=1e6+10; |