前面的文章我介绍了RNN循环神经网络,在最后提了一些关于RNN神经网络的一些问题。今天我们就要针对RNN神经网络存在的问题介绍一个改进版本——LSTM神经网络。
毋庸置疑,RNNs在语音识别、语言建模、翻译、图像字幕等方面取得了令人难以置信的成功!但是,目前很多的应用并不是基于标准的RNN,而是对RNN进行改进的版本,LSTM神经网络通过对RNN的机制做了一些更加复杂的改进而成功地站上了主流舞台。
长期依赖问题
首先想要弄明白LSTM就得先充分理解是哪些因素导致了RNN出现梯度爆炸和梯度消失的问题,所以我们需要深度挖掘一下是什么导致了梯度爆炸和梯度消失的问题呢?
在RNN的文章里我举了一个例子,说是我们的时间线拉的特别长,我们需要让RNN记住全部的信息,然后我们利用公式推导的W要不断地连乘,然后就导致越乘越大,或者是越乘越小。好的,如果让你去解决这个问题,你会怎么解决呢?
你肯定会觉得时间线太长了,会想要试图去缩短这根时间线,我们可以只让神经网络记住最近的信息,遥远的记忆就直接忘记算了,我们可以举个例子,假设我们的朋友问我们告诉我们三件事情:“诶那个谁谁谁又找对象了,有家店的什么什么东西特别好吃,我们今天晚上去不去那里?”。我们需要让神经网络记住所有的信息吗,好像并不需要,特别是1和2,3明显是分开的,我们分析第二句和第三句的时候很明显不需要再去分析第一句了。
那么问题来了,我们似乎得手动设置一个长度来控制信息是否过期,这个就非常头疼了。人类的语言和情感是相当复杂的,我们并不能找到一个定理说“在24小时后你说的这句话一定就是废话!”相反,我们完全可以举出反例说有些话即使经过了很长很长的时间仍然非常有用,是关键信息。比如,有人今天跟你说:“借我100大洋,我下个月还你。”那么,这条信息的保质期就非常长了,当下个月你去找他聊天的时候,谈到钱这个关键词的时候,你说“还我100”类似的话的几率就相当高了。
这个例子确实非常重要,如果我们的神经网络是手动设置长度,那么想当然地假如你们这一个月内疯狂聊天,并且所有的话都被录入了神经网络,然后你又非常大方地在一个月内没有提起过还钱。那么,如果你想让RNN成功预测你在准时一个月后会管他要钱,你总不能为了这一条记住一个月内的所有信息吧。假设你只分析了一天之内的聊天信息,那么机器连他欠你钱都不知道。。。能预测出还钱才是见鬼了呢。
再举一个例子, 大家基本上都读过侦探小说吧。我们如果想让我们的机器判断出凶手,我们总得分析所有的事情吧,不能说这里我设置一个时间把前面的线索全都忘了再去判断吧。
所以,科学家们得出的结论是,为了保险起见,必须得分析所有的时间点,不能不负责任地忘记某些信息。
那么,问题又来了,如何既能保留住有效的信息,又能够缩短序列呢?科学家们想了一个办法,我们可不可以设置如同过滤网一样的东西,每一个单元就对信息做一次筛选,把有用的信息保存,把没用的信息删掉呢?然后学术界一顿捣鼓,就出来了LSTM神经网络。
LSTM神经网络介绍
LSTM的设计就是为了避免长期依赖问题。长时间记忆信息实际上是他们的默认行为,而不是他们努力学习的东西!
所有的递归神经网络都具有一系列神经网络重复模块的形式。在标准的RNNs中,这个重复的模块有一个非常简单的结构,比如一个单一的tanh层。如下图就是标准RNN单元
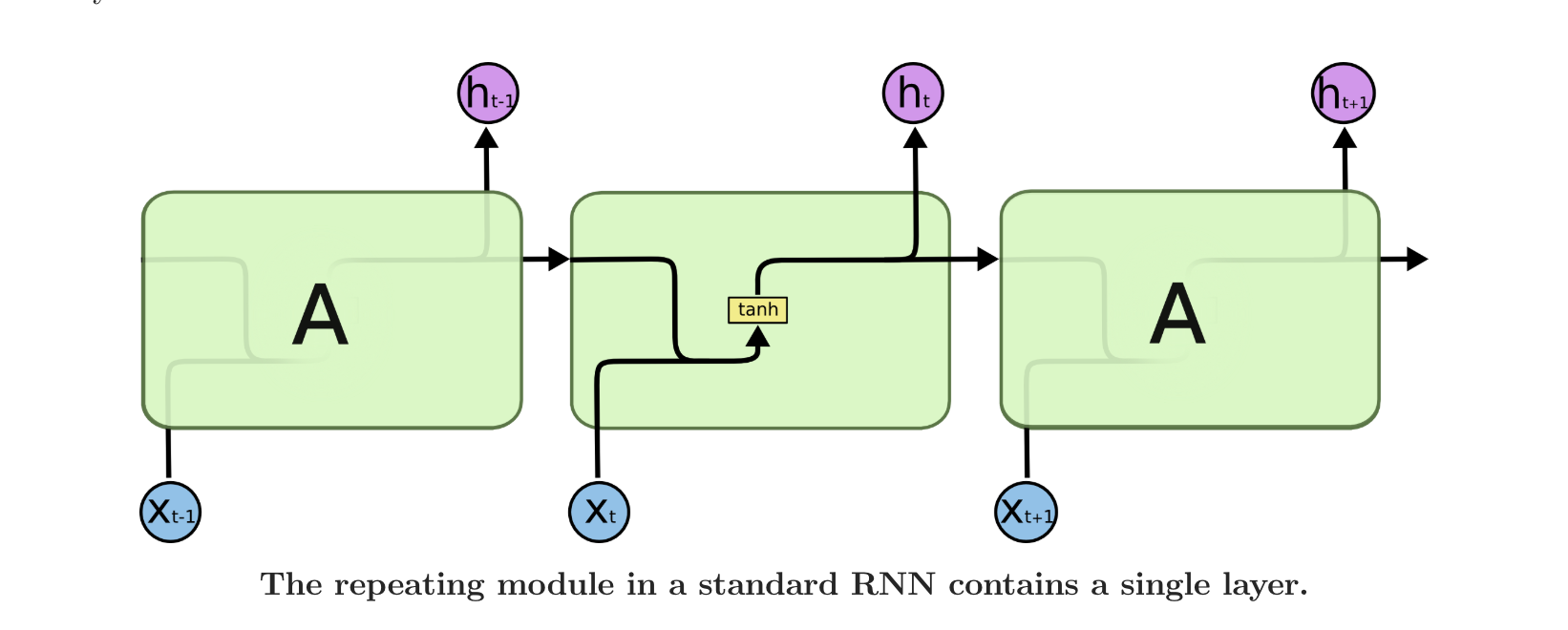
我们可以看到标准RNN的单元结构非常简单,但是LSTM就要复杂多了,请看下面的LSTM神经网络的单元
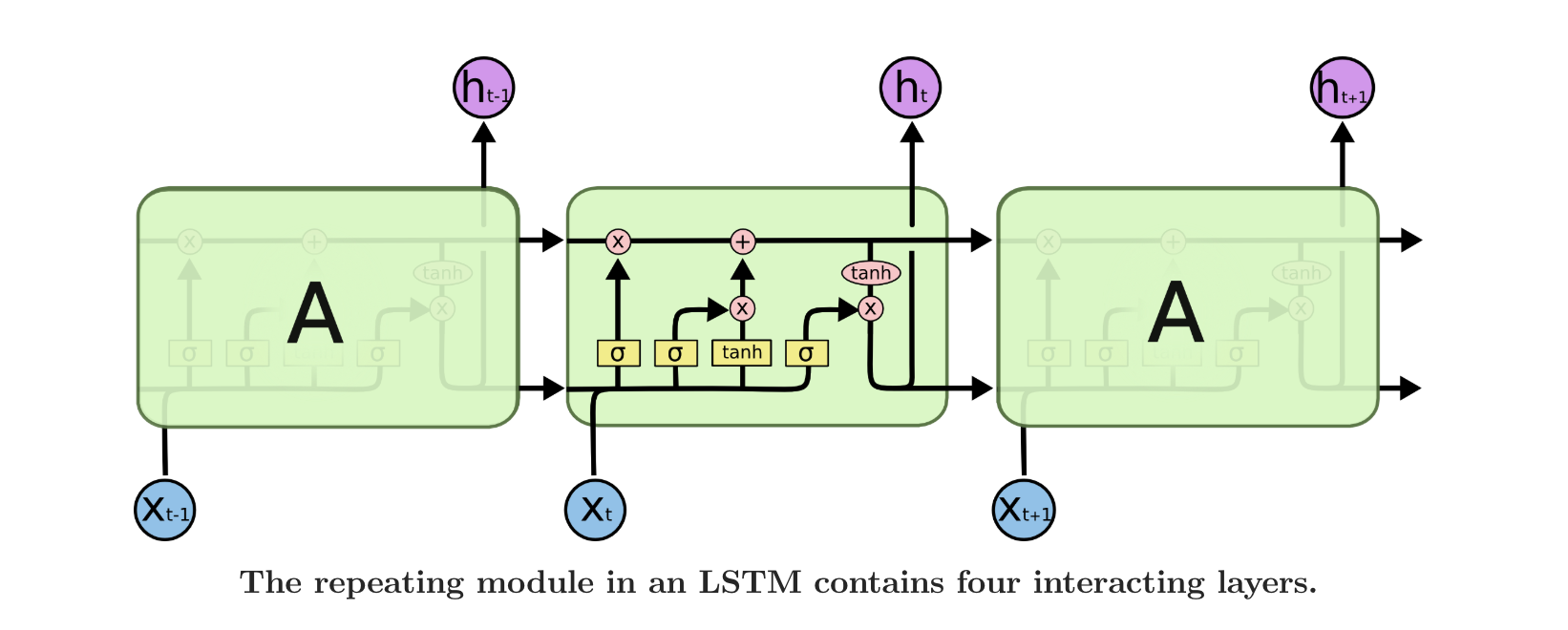
我们看到这个图就非常复杂了,我们一会儿完整地剖析一下,首先我们来介绍一下符号的意思

在上面的图中,每一根黑色的线都携带一个完整的向量,就是从一个节点的输出到其他节点的输入。粉色的圆圈表示向量与向量之间的计算,比如向量加法,而黄色的方框表示学习神经网络层。行合并表示连接,而行分叉表示要复制的内容和要到不同位置的副本。
好,理解了符号的意思,我们就来剖析一下具体的结构吧!
核心思想
首先LSTM神经网络保留了RNN那一条主要的时间链,仍然将过去的信息传到将来,所以下图中我们就看到了顶部的这条线
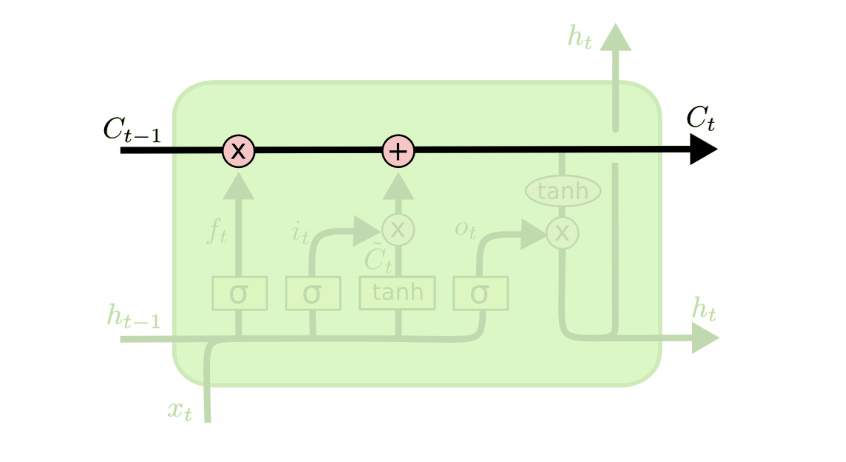
但是我们看到不一样的是,这条链上有两个粉色的圈圈,一个是向量乘法,一个是向量加法,都是从下面上来的数据对我们已经在时间线上的数据进行操作,所以我们先看一部分,也就是乘法操作,乘法操作和下面的结构被称为“门”,功能很像数字逻辑里的门电路。先看图
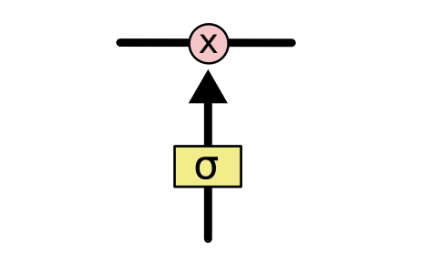
我们仔细观察黄色的那个矩形,里面是sigmoid函数,sigmoid函数的作用就是把其他的数值变成0~1之间的数字,然后我们用0~1之间的数值去乘上时间链上的数据,那不就是对数据做了筛选么?如果乘的数字偏近于1,就相当于对数据进行了保留,允许这一段数据保留下来,如果乘的数字偏近0,就相当于进行了过滤,将这些不要的数据成分变少。
遗忘门、输入门与输出门
遗忘门
首先我们先来介绍遗忘门,先看下图
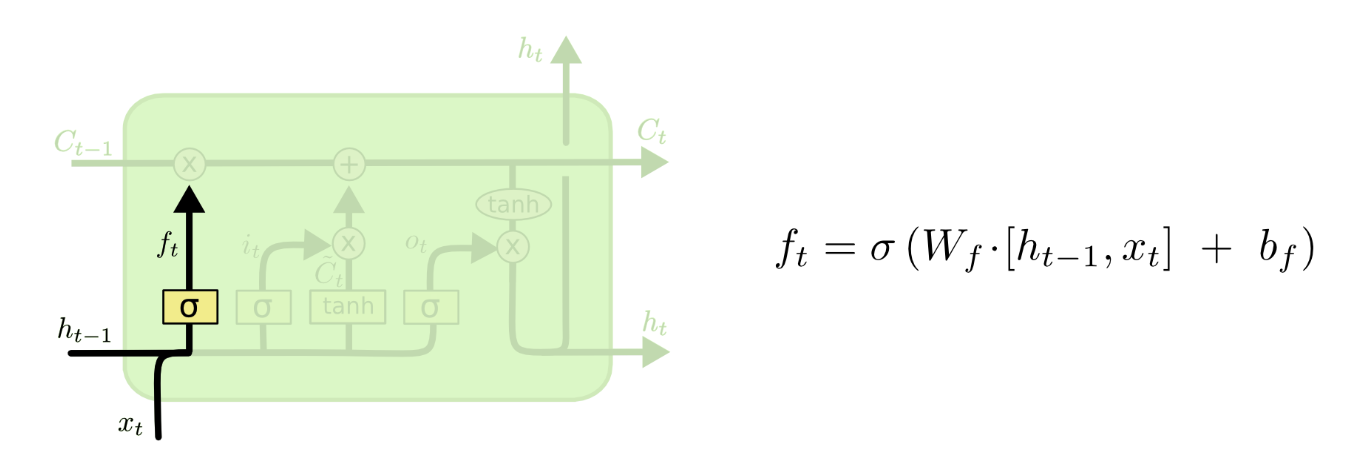
首先我们看到下面的x和h合并了,我们可以发现那个h是上一个单元的输出信息,我们将上一个单元的输出与这个单元的输入合并,然后使用sigmoid函数,在这之后,sigmoid函数会为前面的C向量的每个信息输出0~1之间的数字,也就是选择要不要保留前面的信息,也就是选择是否遗忘前面的信息,这样就起到了筛选的作用。
输入门
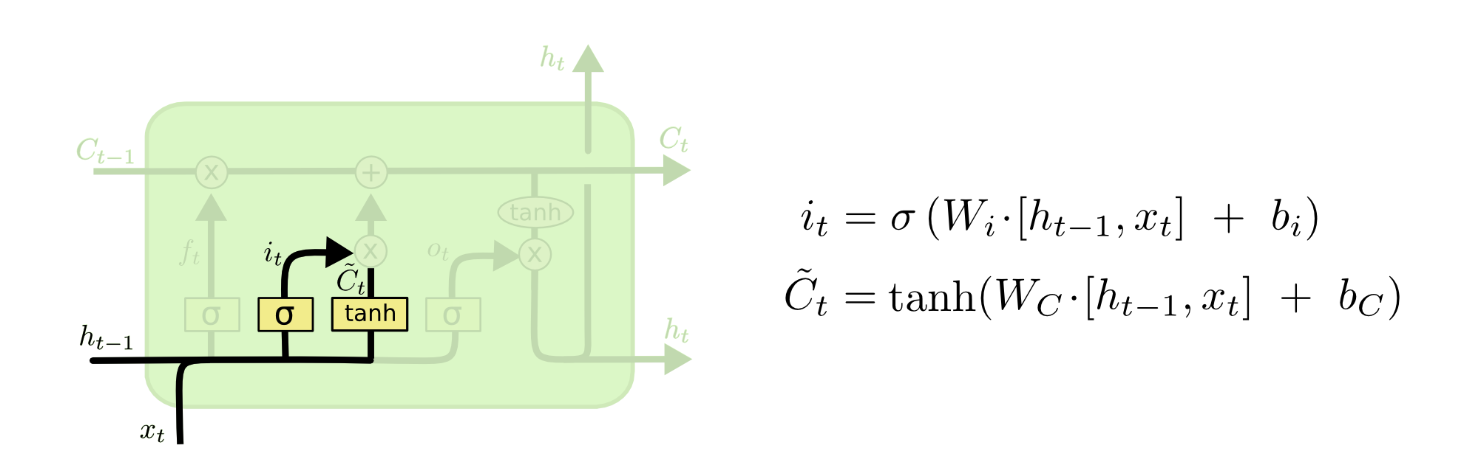
我们刚才讲了遗忘,那么我们既然把前面的信息遗忘了,如果不加入新的信息加以代替,就会导致我们的信息越传越少。当然,对于新信息我们也不能一昧地加入,因为前面的垃圾信息已经被遗忘门去除了大部分,我们不能因为加入了当前的垃圾信息然后导致当前单元的输出不准,所以我们需要对当前的输入也做筛选然后将其加入(这也就是为什么有一个乘法操作然后后面又有一个加法操作的原因)。
我们将其分成两部分,首先是tanh函数那一部分,tanh函数在这里作为一个激活函数(输入到输出的映射,如果不理解激活函数请百度),tanh函数出来的值就像是选秀节目候选区的选手,等着评委将他们中出色的选走,那么我们很容易通过遗忘门的sigmoid函数来理解,这不又是一次过滤嘛!只不过这次过滤的只是输出而已,sigmoid函数就像评委,一个个对输入做筛选,将优秀保留下来加进最顶端的传送链中。
长期依赖问题的解决
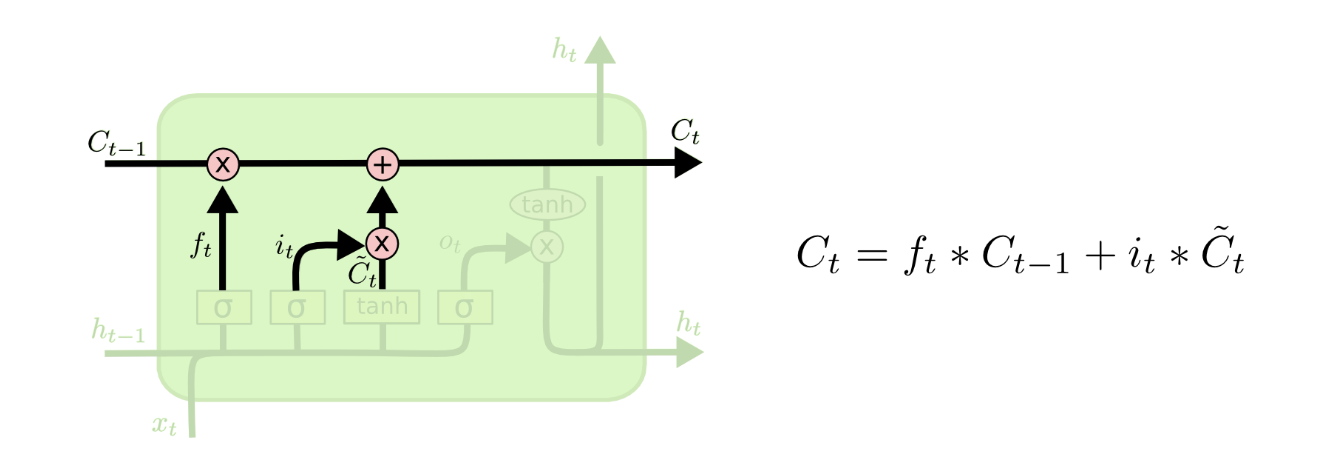
至此我们对C的部分的操作都已经完成了,我们可以看到LSTM通过两个部分的操作就完成了RNN解决不了的问题,首先对时间链上的元素做一次筛选,当筛选后数据丢了很多,我们就对输入和上一次的输出合并后再做一次筛选然后加入到时间链中。这样长此以往我们就能充分保留有用的数据,但是数据的规模也不会扩大,不会导致模型过于复杂、时间链太长而爆炸。
输出门
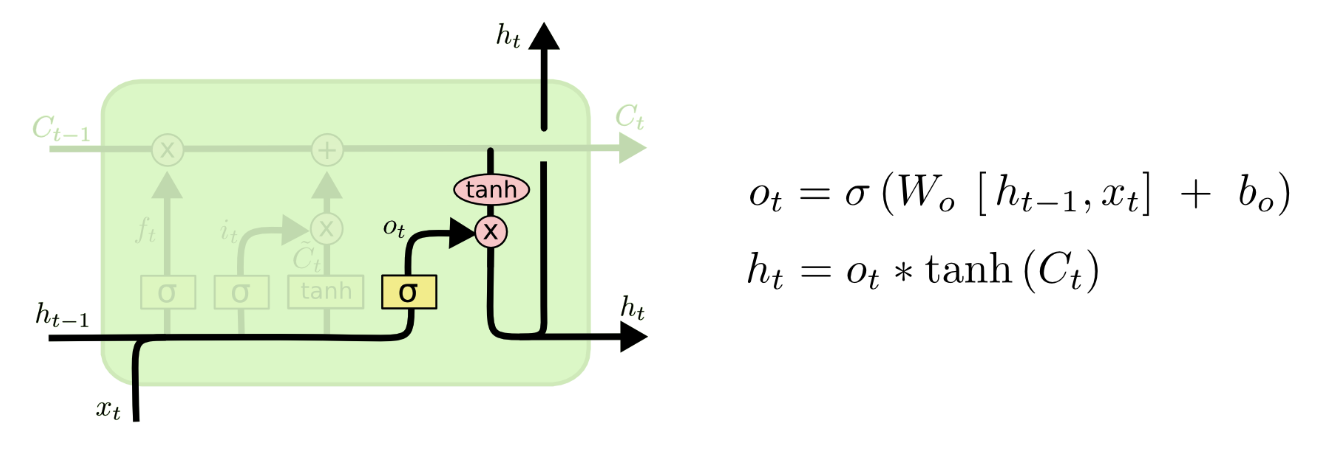
我们看到输出门的主要的信息都是从上面那条链引下来的,上面的链的数据经过了一个tanh激活函数后,再使用前面的sigmoid函数再次筛选然后输出。
LSTM神经网络变种
窥视孔连接
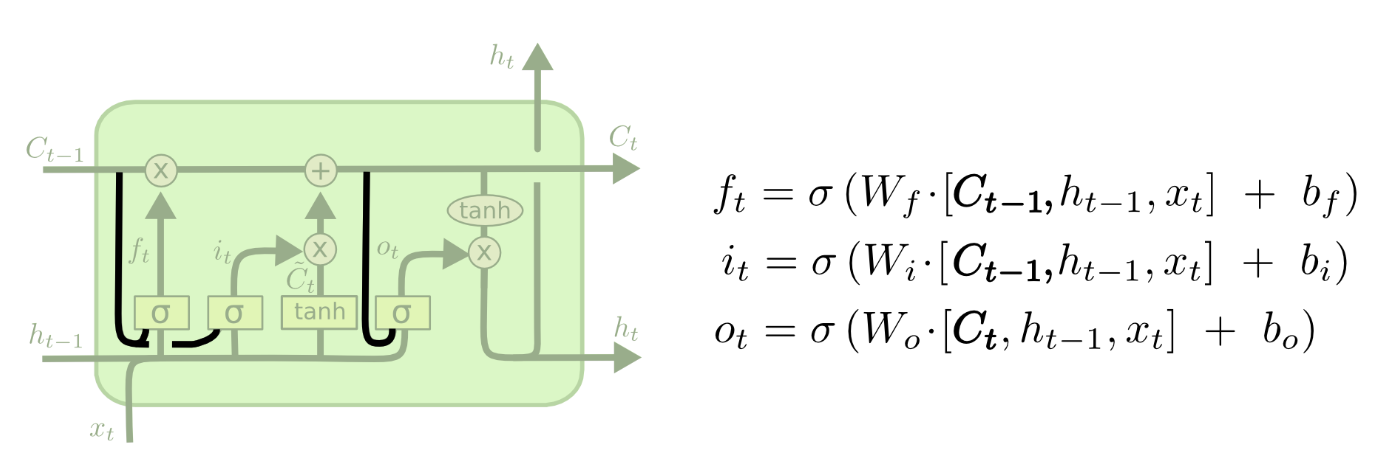
一个流行的LSTM变种,由Gers & Schmidhuber (2000)提出,加入了“窥视孔连接(peephole connection)”。也就是说我们让各种门可以观察到链中的状态。上图中,对于所有的门都加入了“窥视孔”,不过也有一些论文中只加一部分。
对偶的遗忘门和输入门
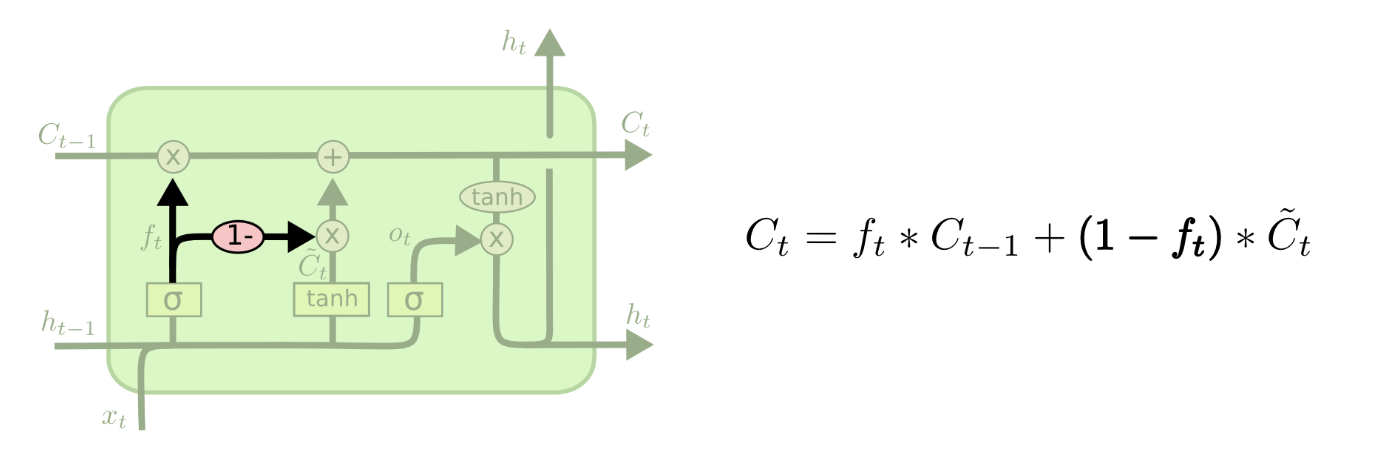
另一种变种是使用对偶的遗忘门和输入门。我们不再是单独地决定需要遗忘什么信息,需要加入什么新信息,而是一起做决定:我们只会在需要在某处放入新信息时忘记该处的旧值,我们只会在已经忘记旧值的位置放入新值。
GRU神经网络
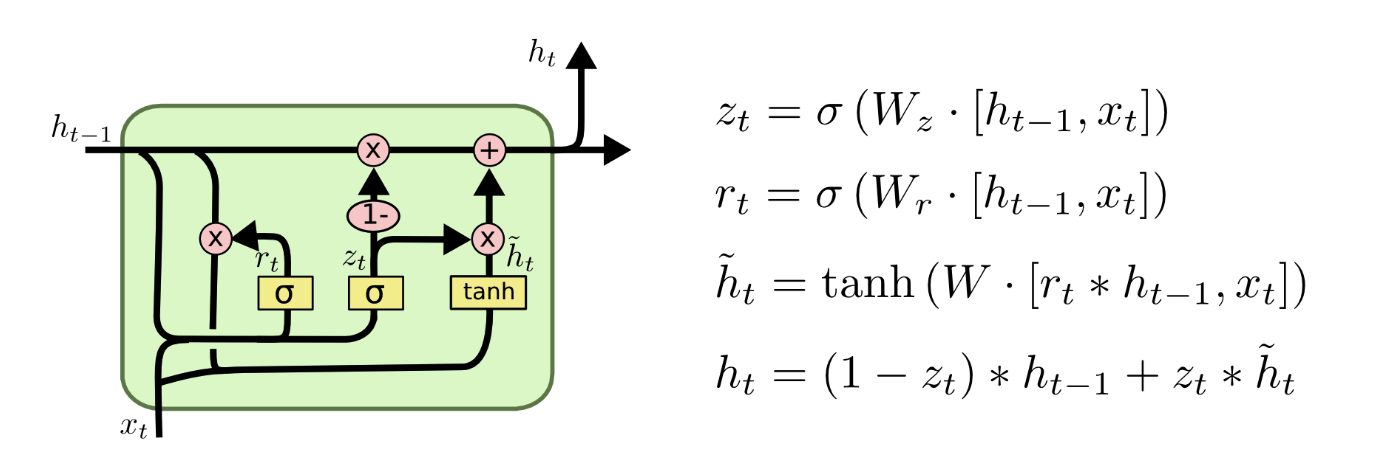
另一个变化更大一些的LSTM变种叫做Gated Recurrent Unit,或者GRU,由Cho, et al. (2014)提出。GRU将遗忘门和输入门合并成为单一的“更新门(Update Gate)”。GRU同时也将元胞状态(Cell State)和隐状态(Hidden State)合并,同时引入其他的一些变化。该模型比标准的LSTM模型更加简化,同时现在也变得越来越流行。
图片来源
图片主要参考的是Christopher Olah的博客,下面给出传送门:
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
写在最后
终于码完这篇博文了,简直写到要吐,希望大家可以学到点东西吧!