这篇博客我来简要地介绍一下RNN神经网络,当然也是为了学校里的比赛写的技术文档。首先申明一点,网上有非常多的介绍RNN神经网络的优秀的文章(很可能写得都比我好),我只是基于国外大神的文章做一些自己的理解,尽量保证通俗易懂,如果语言不严谨请见谅,毕竟我也不是搞学术的。
什么是RNN
循环神经网络,Recurrent Neural Network。如果不熟悉神经网络的同学可以自己先去看看普通的神经网络,再来学习RNN。如果已经能搞懂普通的神经网络了,那么理解这个RNN也并不会太难。
首先我们要知道RNN神经网络是用来处理什么样的问题的,我可以举出一个例子。我们知道普通的神经网络只接受一组输入(假定为一个向量x),然后通过把这组输入放进神经网络模型中跑,wx+b然后加上Relu或sigmoid等等,然后神经网络会输出一组向量,这就是你的预测值,之后根据预测值跟真实值比较,算出误差,再反向传播去修改神经网络中的参数以期望下一组数据进来的时候能预测得更准,久而久之我们就会得到一个相对准确的神经网络,就可以愉快地玩耍啦!
But,脑洞大的人就发现了问题所在。我们细想就能发现,如果使用普通的神经网络,每次我们输入的数据都是独立于其他数据的,这一点非常关键和致命。我们更加细致讲解一下这个问题:假设我们有三个输入数据,也就是三个向量x1,x2,x3,首先第一个时刻一定是x1冲锋陷阵,x1走进神经网络中得到输出y1,然后神经网络通过y1和真实值比较修改了神经网络中一些单元的参数,然后,就把x1给扔了。。。同理,x2走了一遍流程,完成了它的任务也光荣下岗了。这时候x3走进神经网络,它眼前只有一个庞大的神经网络,它根本就不会知道x1,x2是什么东西,它根本就看不到x1和x2,假如这三个数据是有关系的,普通的神经网络直接会把这三个数据之间的关系拆散。
那么,现实生活中所有数据之间都没有联系吗?举个例子,我们平常说话,一些了解你的好朋友非常了解你的口头禅,你这句话没说完呢它马上就知道你想说什么以及你后面的话,假设我们把你的口头禅放进神经网络里去训练,以期望你的神经网络能够像你的老朋友一样能猜出你接下来要说的话。那么我们会发现,对于一个普通的神经网络,好像做这种事情挺困难的,因为上面提到过,普通的神经网络对于多组输入之间是没有联系的。比如,你的口头禅是“你神经病吧”,那么,你需要让你的神经网络在你说出“你神经”这三个字之后成功预测你下一个要说的字是“病”。但是普通的神经网络在你输入“你神”之后就会把这两个字丢掉,然后在第三个字“经”进去的时候就单独在神经网络中跑,然后神经网络很可能并不会认识“经病”这个词,很可能它反而会更认识“经过”、“经历”这些词语,然后你发现你的神经网络的效果就非常差了。
我们来开一下脑洞来想想我们该怎么解决这个问题,很明显我们得给神经网络加上“记忆”,不能让它接受了下一个输入就忘记了上一个输入,还是那个“你神经病吧”这个例子,我们能不能变通一下,第一次我们的输入是“你”,然后下一次的输入是“你神”,再下一次是“你神经”,然后我们根据“你神经”的输入加上前面训练好的神经网络让机器输出“病”这个字。
下面这张图片就是拿“hello”举的例子,请注意我中间用黑圈圈出来的那些线,这就是RNN网络不同于一般神经网络的地方
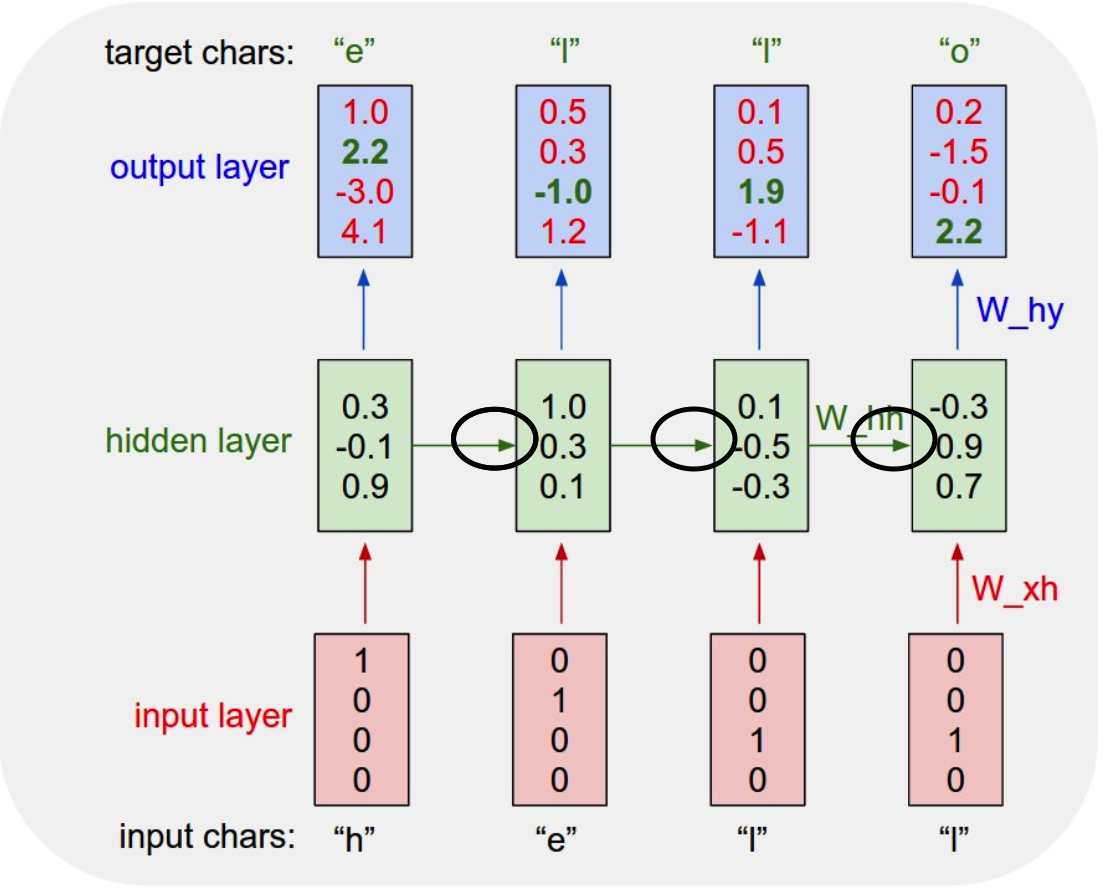
我们可以看到,增加了黑圈圈住的路径之后,我们输入第一个“h”之后神经网络不仅仅只做输出的工作,它会将经过了隐藏层操作后的输入作为下一个单元的输入,然后和下一个单元的输入“e”一起构成一个完整的输入,那么我们在预测“l”的时候就不仅仅会考虑“e”,还会连着前面的“h”一起考虑进去,同理,第三个单元不仅仅会只考虑“l”,而是会考虑前面的“hel”,以此类推,我们会发现这个神经网络就像有了记忆功能一样,可以记住前面的信息,这样我们就避免了普通神经网络的无法保存输入之间的联系的问题。
再仔细观察上面的图片,我们会发现输入层是一个向量,里面的数字分别对应着四个字符:h,e,l,o。当向量为1000时说明第一个字符“h”被点亮了,这个应该都能理解吧。我们再说说输出的向量,输出的向量代表了每一个字符的可能性,居第一个单元的例子,第一个单元的输出是h的值为1.0,是e的值为2.2,是l的值为-3.0,是o的值为4.1,那么我们的神经网络就会预测下一个字符是o(因为o的数值最大),但是很明显它预测的是错的,这样我们就要对它进行梯度下降,我们利用反向传播算法调整hidden layer的参数,然后我们进入下一个单元继续进行这样的操作,做很多很多次,最后我们神经网络hidden layer的参数就会相对准确,能够准确预测下一个字符。
那么有人会问,为什么它叫做循环神经网络呢?其实这个很好解释,很多时候你在网上看到的循环神经网络并不会像上图这样是展开的,一般网上贴的RNN都是讲展开的网络收缩,变成下图这样的示意图
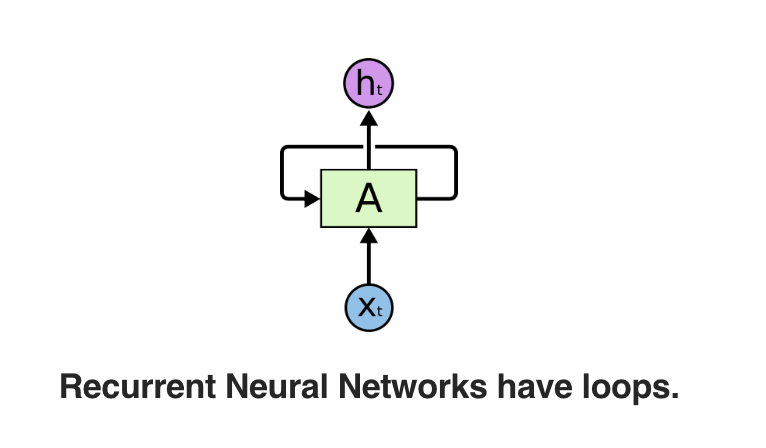
这就是收缩的示意图,我们看到有一条线从右边出来又回到了左边,这个就可以看成我们前面那个展开图的我用黑圈画出来的边,代表的意思当然也是相同的啦。
RNN多种形态的应用
前面的RNN我们只举了一个例子,就是语言方面的例子,当然我们的RNN解决这方面的问题无疑是相当出色的,那么RNN还能应用到哪些方面呢?
接下来放出一张RNN的多种形态的图片,RNN的应用场景大致可以分成三种
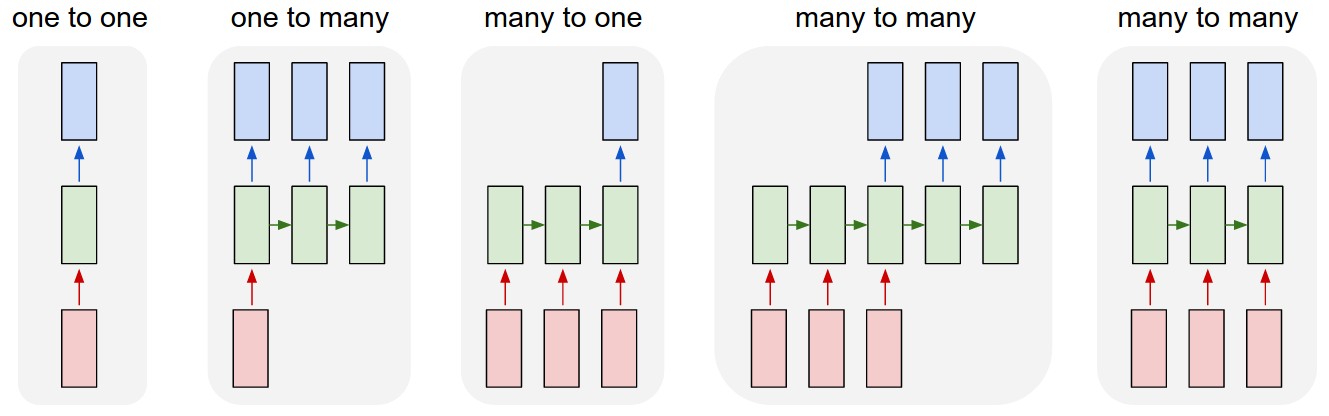
我们忽略最左边的那个,后面的四个就是RNN应用的不同类型的场景。
首先是一对多的场景,这种场景举个例子就像我练习过的写诗的场景,我在训练完写诗的神经网络之后,我只要输入开头的第一字,机器就会自动往下写出一首诗,这就是一个一对多的典型的例子,经常是多对多训练好神经网络然后使用一对多输出。
然后是多对一的场景,多对一的RNN经常适用于文本分类,情感分析问题,经常就是一大堆输入,然后输出只有一个,比如文本分类就是,给了整段的文本,最后神经网络也就是输出一个向量来分类。
最后是多对多的场景,多对多的场景上面那个hello已经举过例子了,就不赘述了,当然对于这种多对多的应用场景,有一个专业的名词叫做seq2seq,也就是Sequence to Sequence。
RNN的数学推导
这一节相对来讲就比较枯燥难懂一些,如果不想看公式的同学可以跳过,等用到了再找公式也行。
RNN前向输出
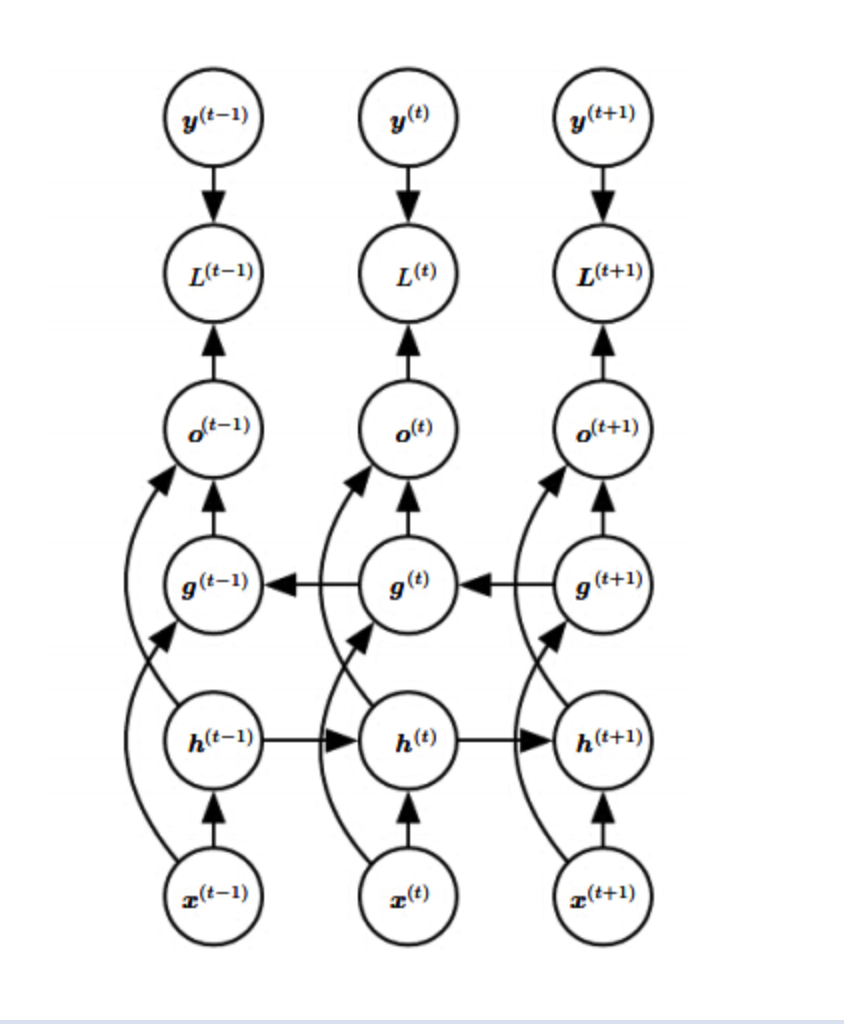
首先我们来讲一下前向传播的过程,先放上图片
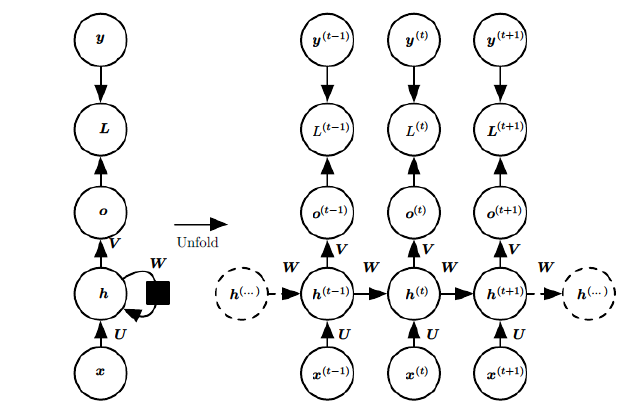
这里我们将x作为输入,h就是hidden layer(隐藏层),o为输出,L为损失函数(就是预测值和真实值的差距),那么y就是真实值了(L是用o和y算出来的),V、W、U是权值,我们可以看到前向传播就非常简单了
其中ϕ()为激活函数,一般来说会选择tanh函数,b为偏置。
其实说白了就是对上一个的输出乘上一个权值,再将输入乘上一个权值,然后将结果往后面的单元传播,最后再乘上一个权值作为输出。
t时刻的输出就更为简单:
```o(t)=Vh(t)+co(t)=Vh(t)+c
最终模型的预测输出为:
yˆ(t)=σ(o(t))
其中σ为激活函数,通常RNN用于分类,故这里一般用softmax函数。
RNN反向传播
熟悉神经网络的同学可以知道我们常使用BP算法训练神经网络,当然,RNN增加了记忆功能,当然不能用普通的BP算法,所以科学家们稍加改进,发明了BPTT算法(back-propagation through time),其含义就是随着时间进行反向传播,核心思想与BP算法一致,只是增加了随着时间链的梯度下降。
还是神经网络那一套,我们需要进行求偏导然后沿着梯度每次往下降最快的方向走出一小步,久而久之我们的RNN的参数就可以变得比较合理了。
我们对V,W,U三个参数进行进一步的观察。
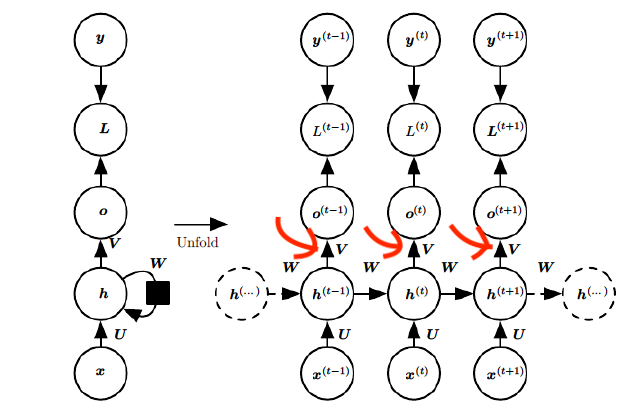
针对于输出的函数V我们只需要求一次偏导就行了,因为V并没有历史数据,因为上图的V之间并没有什么时间顺序上的关系,当然最后计算损失函数需要将每个输出位置上的损失值都进行累加,所以就得出下面的式子
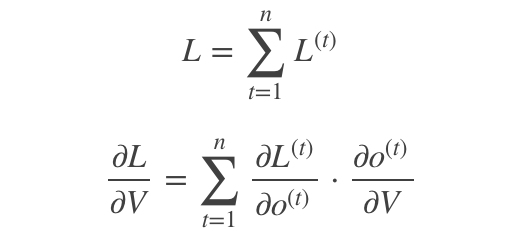
然后就是对U、W进行分析了,因为这两个差不多,都要随着时间链求偏导,所以我就只放一个图了,来!上图!
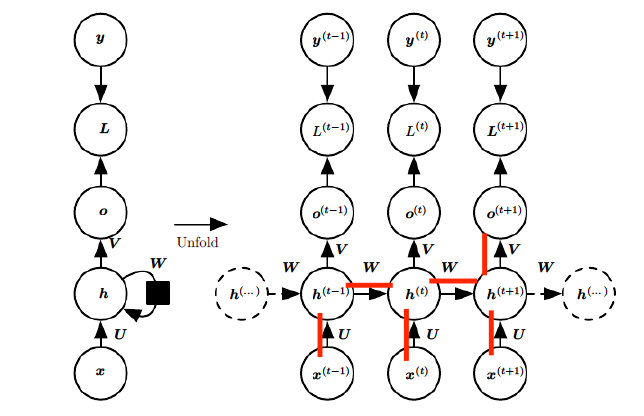
上面图中画横线的就是我们需要反向传播求偏导的路线,我们可以拿三个单元举例子,写一下U和W的公式
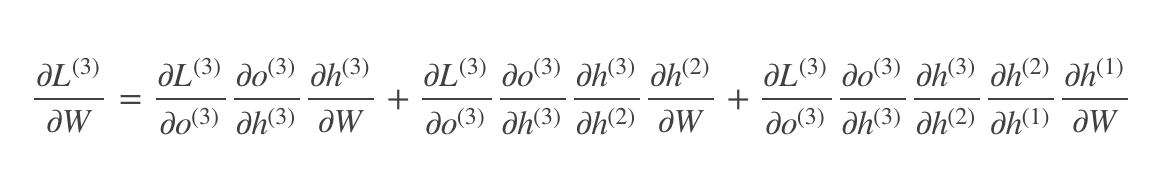
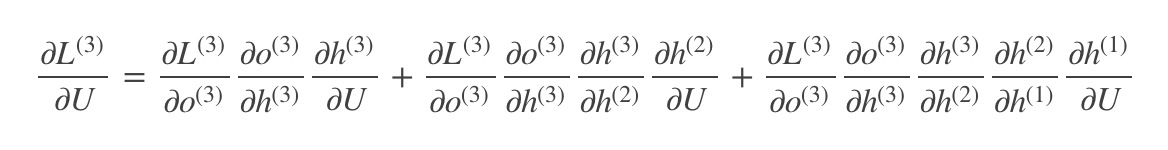
就是沿着时间线一直求偏导,这个公式看上去非常复杂了,我们简化一下,变成下面这样
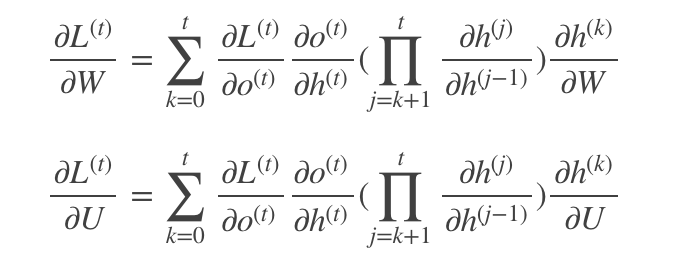
我们再把中间层的h换成激活函数和W,可以得到

这个和上面那个公式合起来就是我们BPTT推导出来的公式了,当然这个连乘会导致RNN出现问题,这个就要进入我们的下一节了。
RNN存在的问题
接下来我们来说一下RNN存在的一些问题。
梯度消失和梯度爆炸
刚才我们说到了求偏导的过程中我们推导出了连乘,那么这个连乘为什么会有这么大的杀伤力呢,原因就在于那条时间序列。
我们知道我们使用RNN是用来解决序列问题的,那么不可避免地我们的时间线可能会拉得很长,举个例子,假设我们让RNN去预测一本小说的结局,或者说预测小说的发现或者续写小说,我们是不是得首先把小说前面所有的剧情全部放到RNN里,我们假设RNN沿着小说第一章的时间线开始跑,一直跑到假设1024章(我们假定这是一个长篇小说),当我们从最后一个单元一直求偏导跑到第一个单元时,我们完全可以统计一下连接hidden layer的W参数乘了多少次,那么我们假定w是1.1,我们假设连续乘1000次W,也就是1.1的1000次方,我们会发现这个数字大到可怕,反过来讲,假设w是0.9,我们求一下0.9的1000次方,简直太小了有木有!
那么试想一下,如果我们的输入真的这么长,到时候W数值就有两种可能了。第一种是大到爆炸,这就被称作梯度爆炸,第二种是小到近似没有了,这就被称为梯度消失。那么,无论是哪一种情况,都将是梯度下降的灾难,我们的梯度下降根本就派不上用场了。
梯度消失和梯度爆炸的一些解决方案
首先我们可以进行预训练加微调,此方法来自Hinton在2006年发表的一篇论文,Hinton为了解决梯度的问题,提出采取无监督逐层训练方法,其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”;在预训练完成后,再对整个网络进行“微调”。
当然我们也可以通过较好的初始化加上ReLU激活函数试试能不能避免这种情况。
截断的BPTT算法也可以解决,这里就不细说了。
我们最终还可以通过改进模型来解决这个问题,LSTM、GRU单元是解决这种长期依赖问题的利器,我下一篇博客就将细讲一下LSTM神经网络。
RNN模型拓展
根据传统RNN,学者们又发展出了许多优化版本。
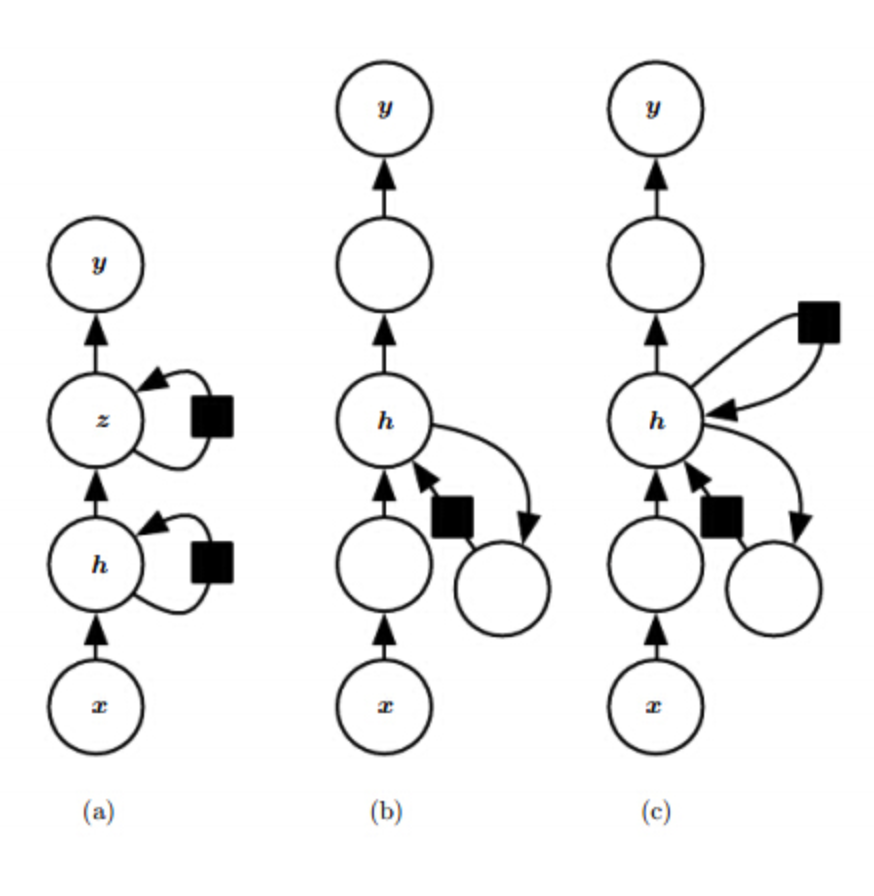
双向RNN
各种版本的深度RNN
图片来源
图片主要是来自于Andrej的博客和Christopher Olah的博客,两位大佬的文章写得非常通俗易懂,还参考了CSDN的两篇文章,基本我都是以自己的话概括这些大佬们的理论,应该还算比较通俗易懂。
下面是参考文章链接:
Andrej的博客:https://karpathy.github.io/2015/05/21/rnn-effectiveness/
Christopher Olah的博客:https://colah.github.io/posts/2015-08-Understanding-LSTMs/
CSDN的两篇文章:
https://blog.csdn.net/zhaojc1995/article/details/80572098
https://blog.csdn.net/fangqingan_java/article/details/53014085
写在最后
终于完成了这篇大文章,这篇文章刷新了我博客迄今为止的最长博文的记录,确实想要系统地讲明白循环神经网络还是非常不容易滴!构思了好久,总共花了一天的时间完成了这篇博文。我可能在理论深度上是远远不及那些大佬的,但是我也算是拿自己的话讲述了一遍,应该会比较通俗易懂吧,希望能帮助到愿意学习RNN的同学。
最后预告一波,下一篇博文是LSTM神经网络,规模应该也不会小哈哈。
