哈哈,疯狂更新!又是八数码问题,这次是写另一种判重方法,也是一种比较常用的方法/数据结构
上一篇文章中的八数码问题中可以不使用康托展开,虽然康托展开是完美哈希(一一对应)的,但是就是因为其完美哈希(一一对应)的这个特质,所以在节点多入牛毛时,你的内存空间还是会爆炸,因为就算康托展开地再完美,也还是无法减少情况,毕竟是一一对应,根本减少不了好吧。所以,在康托都救不了你了,Hash还是可以拯救你一下子的。
接下来就是数据结构的知识了,我们推出主角——哈希表(散列表) 哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。 记录的存储位置=f(关键字) 这里的对应关系f称为散列函数,又称为哈希(Hash函数),采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。
数组的特点是:寻址容易,插入和删除困难; 而链表的特点是:寻址困难,插入和删除容易。 我们综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组”,如图: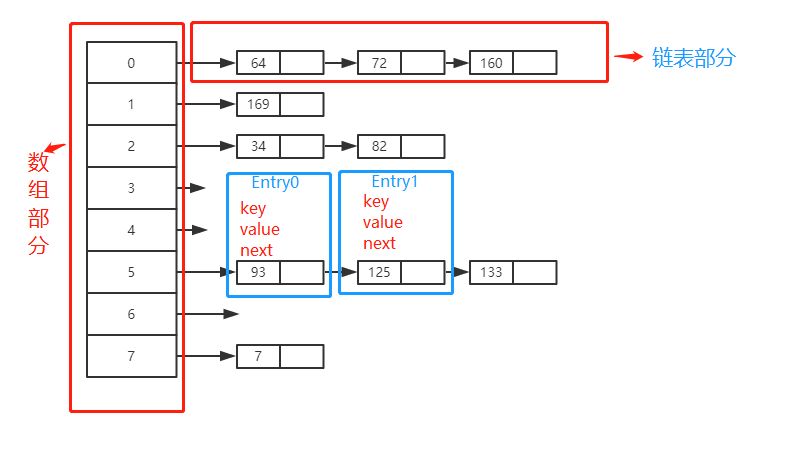
左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。 然后当我们查找时,我们只需要查找一个范围,也就是使用O(1)时间查到这个链表头,之后再进行普通的比较是否一样
小tips:我们在选取hash函数时必须要慎重,举个例子,如果你的hash函数把所有的状态全部映射成了一个值,那么你的哈希表也就只有一条链表了,那这就非常糟糕了。
关键字——散列函数(哈希函数)——散列地址
优点:一对一的查找效率很高;
缺点:一个关键字可能对应多个散列地址;需要查找一个范围时,效果不好;有时候会退化成几条长长的链表。
散列冲突:不同的关键字经过散列函数的计算得到了相同的散列地址。 好的散列函数=计算简单+分布均匀(计算得到的散列地址分布均匀) 哈希表是种数据结构,它可以提供快速的插入操作和查找操作。
优缺点
优点:不论哈希表中有多少数据,查找、插入、删除(有时包括删除)只需要接近常量的时间即0(1)的时间级。实际上,这只需要几条机器指令。 哈希表运算得非常快,在计算机程序中,如果需要在一秒种内查找上千条记录通常使用哈希表(例如拼写检查器)哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。哈希表不仅速度快,编程实现也相对容易。 如果不需要有序遍历数据,并且可以提前预测数据量的大小。那么哈希表在速度和易用性方面是无与伦比的。
缺点:它是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,性能下降得非常严重,所以程序员必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程)。
代码实现(以前一篇博客的八数码问题举例):
1 |
|
OK,哈希表的问题我们就说到这里,明天更新一个有趣的倒水问题。
PS:暑假期间博客争取日更,不知道这是不是一个FLAG